We recently released new open source code for Colossal-AI, which enables you to use it as a framework for replicating the training process of OpenAI’s popular ChatGPT application optimized for speed and efficiency.
With Colossal-AI's efficient implementation of RLHF (Reinforcement Learning with Human Feedback), you can get started on replicating the ChatGPT training process with just 1.6GB of GPU memory, and experience a 7.73 times acceleration in the training process. Our open-source solution is designed to be developer-friendly, with a simple main entrypoint and multiple training strategies to choose from.
Whether you're a seasoned machine learning practitioner, beginner, or researcher; a startup looking to implement custom AI applications; or an enterprise looking to leverage the power of AI for your business, continue reading to benefit from valuable resources for anyone interested in replicating the ChatGPT training process using Colossal-AI.
Use Cases for Applications Replicating ChatGPT with Colossal-AI
There are several potential use cases for Colossal-AI's ChatGPT-like solution, including:
- Chatbots: Build conversational AI models that can be integrated into chatbots to provide human-like interactions.
- Virtual Assistants: Train virtual assistant models that can help users with tasks such as scheduling appointments, managing emails, and providing information.
- Recommender Systems: Build recommendation models that can suggest products, services, or content to users based on their interests and behaviors.
- Customer Service: Train customer service models that can respond to customer inquiries in real-time, reducing wait times and improving the overall customer experience.
- Industry-specific solutions: For example, train AI models for chatbots that can assist healthcare professionals in tasks such as diagnosing diseases, predicting patient outcomes, and improving patient care.
Colossal-AI's Features for Implementing ChatGPT-like Solutions
The technical analysis of ChatGPT in relation to Colossal-AI's features is a crucial aspect of understanding the potential of Colossal-AI as a framework for replicating the training process of OpenAI's popular ChatGPT application.
ChatGPT is a state-of-the-art language model developed by OpenAI that uses a deep neural network architecture to generate human-like text. The main components of ChatGPT are the actor and critic models, which are trained using reinforcement learning with human feedback (RLHF). Colossal-AI, on the other hand, provides a platform for training large models such as those related to ChatGPT through its implementation of RLHF. One of the key features of Colossal-AI is its ability to support distributed training and offloading, which enables the training of extremely large models with limited memory resources.
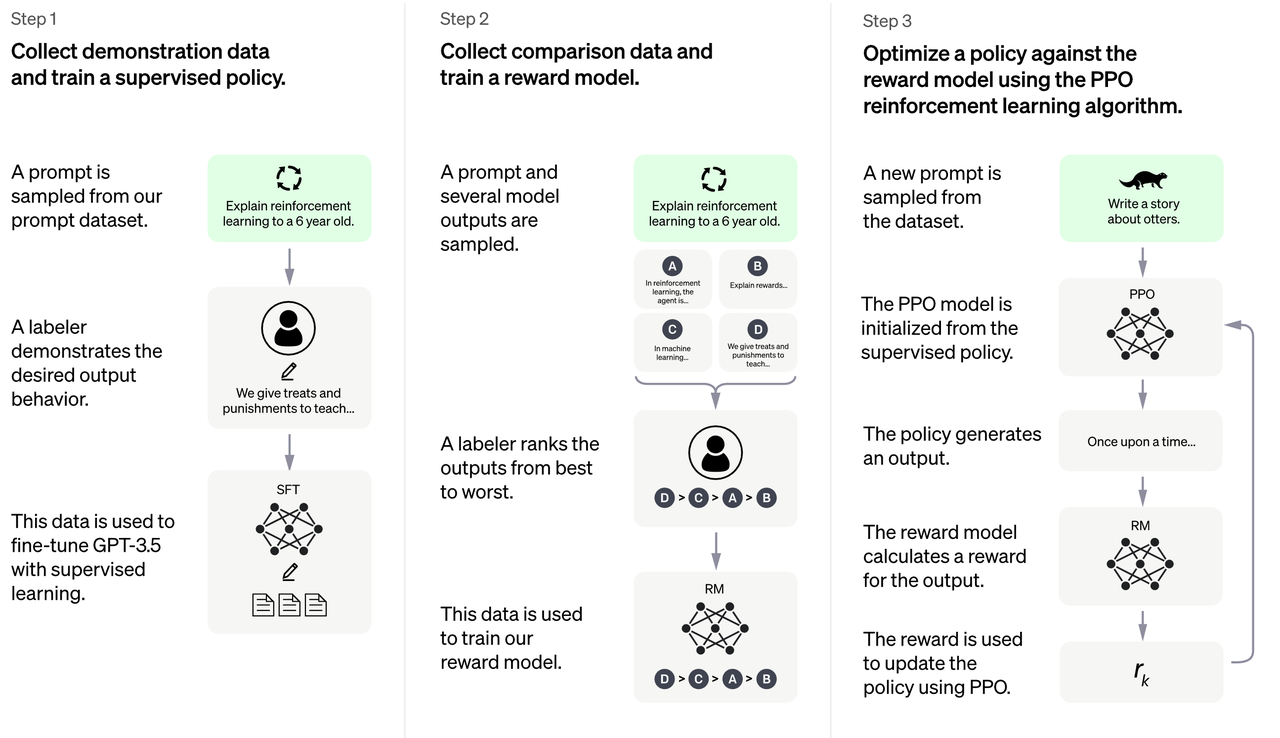
The three stages of the ChatGPT training process can be summarized as follows:
-
Sampling and Fine-tuning: The first stage of the training process involves sampling from the prompt library and collecting human responses. This data is then being used with the help of the InstructGPT tool to fine-tune the pre-trained large language model to better capture human preferences.
-
Sampling and Training a Reward Model: In the second stage, multiple responses are generated using the language model, and then manually ranked based on human preferences. This data is then used to train a reward model (RM) that fits human preference.
-
Reinforcement Learning with Human Feedback: Further training the large language model using reinforcement learning algorithms, based on the supervised fine-tuning model from stage 1 and the reward model from stage 2. This stage, which is the core part of RLHF training, uses the Proximal Policy Optimization (PPO) algorithm in reinforcement learning to introduce the reward signal and generate content more in line with human preference.
To better understand this process, take a look at the following graph outlining the three stages.

A visualization of the InstructGPT language model's ability to follow complex instructions in the context of a recipe task, taken from OpenAI's respective blog post.
Massive Resource Requirements of Original ChatGPT Training Process
The complexity of the ChatGPT model, which is due to the introduction of reinforcement learning, results in many model calls. For example, when using the Actor-Critic (AC) structure with PPO algorithm, the forward inference and back-propagation of both the Actor and Critic models must be conducted, as well as multiple forward inferences of the supervised fine-tuning model and reward model during training. The Actor and supervised fine-tuning models both use the GPT-3 series model with 175 billion parameters, while the Critic and reward models use the GPT-3 series model with 6 billion parameters.
Starting the original ChatGPT training process requires thousands of GB of GPU memory, which is far beyond the capacity of a single GPU and even the common data parallel technology. Even with the introduction of tensor parallelism and pipelining parallelism to partition parameters, at least 64 80GB A100 GPUs are still required as the hardware basis. Additionally, pipelining is not suitable for AIGC's generative tasks due to its complexity and efficiency, making the code reproduction of ChatGPT's training process even more difficult and challenging.
Optimizing ChatGPT-like Training with Colossal-AI: 50% Hardware Savings, 7.73x Faster
Colossal-AI replicates the ChatGPT training process in an open-source manner, including all three stages of pre-training, reward model training, and reinforcement learning training, which is the most complex stage of the process.
Additionally, Colossal-AI reduces the GPU memory overhead of ChatGPT-like training by utilizing advanced memory management techniques. It only requires half the hardware resources to start training a 175 billion parameter model, resulting in significant cost savings for ChatGPT-style applications. With the same hardware resources, Colossal-AI is able to complete training in less time, reducing training costs and accelerating product iterations.
To make the ChatGPT training process more accessible to developers, Colossal-AI provides efficient single-GPU and stand-alone 4/8-GPU versions, in addition to the original 175 billion parameter version, to ease hardware restrictions.

On a single multi-GPU server, even with the highest-end A100 80GB GPU, PyTorch can only launch ChatGPT using small models like GPT-L (774M) due to the complexity and memory fragmentation of the ChatGPT process. As a result, scaling up to 4 or 8 GPUs using PyTorch's DistributedDataParallel (DDP) provides limited performance gains.
Colossal-AI not only provides significant speed and efficiency improvements for single-GPU training, but can also be further improved as parallelism increases. It is 7.73 times faster for single-server training and 1.42 times faster for single-GPU inference, and can continue to scale to large-scale parallelism, reducing the cost of replicating ChatGPT.

To minimize training costs and increase ease of use, Colossal-AI offers a single-GPU version of the ChatGPT-like training process. Compared to PyTorch, which can only start models with up to 780 million parameters on the $14,999 A100 80GB GPU, Colossal-AI increases the capacity of a single GPU by 10.3 times to 8 billion parameters. For replicating the ChatGPT training based on a small model with 120 million parameters, a minimum of 1.62GB of GPU memory is required, which is readily available on any consumer-level GPU.
The comparison of the throughput of PyTorch and Colossal-AI on various devices is shown in the table below, with the starting device being an NVIDIA GeForce RTX 3080 graphics card equipped with 10GB of GPU memory and 128GB of CPU memory.

In addition, Colossal-AI is constantly working to reduce the cost of fine-tuning tasks based on pre-trained large models. For example, for fine-tuning tasks related to the ChatGPT OPT model, Colossal-AI is able to increase the capacity of the fine-tuning model on a single GPU by up to 3.7 times compared to PyTorch, while maintaining high speeds.
Developing a ChatGPT-like Training Process with Colossal-AI's Open Source Framework
Let's dive into the code to see how Colossal-AI makes it easy for AI developers to train models for a solution such as ChatGPT efficiently and cost-effectively.
Colossal-AI offers a ready-to-use ChatGPT training code, allowing users to train popular pre-trained models like GPT, OPT, and BLOOM from the Hugging Face community in a ChatGPT-style manner with ease. To start, simply specify the use of Colossal-AI as a system strategy with just one line of code, as demonstrated with the example of training a GPT model.
from chatgpt.nn import GPTActor, GPTCritic, RewardModel
from chatgpt.trainer import PPOTrainer
from chatgpt.trainer.strategies import ColossalAIStrategy
strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
with strategy.model_init_context():
actor = GPTActor().cuda()
critic = GPTCritic().cuda()
initial_model = deepcopy(actor).cuda()
reward_model = RewardModel(deepcopy(critic.model)).cuda()
trainer = PPOTrainer(strategy, actor, critic, reward_model, initial_model, ...)
trainer.fit(prompts)
With just a few simple commands, you can easily begin training models at the single-GPU scale, single machine multi-GPUs scale, and even the original 175-billion-parameter scale version of ChatGPT. You can also evaluate the performance of your models using indicators such as maximum GPU memory usage, throughput, and TFLOPS.
# Training GPT2-S using a single card, a minimum batch size, Colossal-AI Gemini CPU strategy
torchrun --standalone --nproc_pero_node 1 benchmark_gpt_dummy.py --model s --strategy colossalai_gemini_cpu --experience_batch_size 1 --train_batch_size 1
# Training GPT2-XL with a 4-GPU machine, Colossal-AI Zero2 strategy
torchrun --standalone --nproc_per_node 4 benchmark_gpt_dummy.py --model xl --strategy colossalai_zero2
# Training GPT-3 with 4 8-GPU servers, Colossal-AI Gemini CPU strategy
torchrun --nnodes 4 --nproc_per_node 8 \
--rdzv_id=$JOB_ID --rdzv_backend=c10d --rdzv_endpoint=$HOST_NODE_ADDR \
benchmark_gpt_dummy.py --model 175b --strategy colossalai_gemini_cpu --experience_batch_size 1 --train_batch_size 1
Source Code and Collaboration
- The open source code of Colossal-AI is available at https://github.com/hpcaitech/ColossalAI/tree/main/applications/ChatGPT.
- You can post an issue or submit a pull request (PR).
- Join the Colossal-AI WeChat or Slack group to communicate with the team and other users.
- Learn about the benefits and join our Colossal-AI partner program.
Comments