With the help of multi-dimensional tensor strategy like the 2-dimensional tensor parallelism, Colossal-AI system successfully breaks the GPU memory bottleneck and largely enhances the communication efficiency of super-large AI models. Compared with existing methods, Colossal-AI can improve about 10× maximum model size or training acceleration, and is compatible with other popular methods, including data parallelism, pipeline parallelism, sequence parallelism, ZeRO-Offload, etc.
Open source address: https://github.com/hpcaitech/ColossalAI
Model Parallelism
To tackle the challenges to both software and hardware imposed by super-large models, researchers have proposed pipeline parallelism and tensor parallelism to distribute the parameters of the entire model to multiple devices for computation. Specifically, pipeline parallelism partitions the model by layer structure, with each processor taking input from the previous processor and passing the output to the next processor. Tensor parallelism, such as NVIDIA Megatron, enables distributed computing in multiple processors by splitting the parameter matrices within a layer by row or column, using block matrix multiplication.
NVIDIA Megatron’s tensor parallelism adopts the 1-dimensional matrix partitioning strategy. Although this approach distributes the parameters across multiple processors, each processor still needs to store the whole intermediate activations, which can waste a lot of memory when processing large models. In addition, since only the 1D matrix partitioning is used, each processor needs to communicate with all other processors for each computation, leading to high communication cost surging with the degree of parallelism.
2D Tensor Parallelism
Obviously, 1D tensor parallelism can not meet the needs of current super-large AI models. In this regard, Colossal-AI provides multi-dimensional tensor parallelism, including 2/2.5/3-dimensional tensor parallelism. Taking the 2D tensor parallel behavior as an example, it uses SUMMA 2D matrix multiplication to distribute parameters and activations at the same time to achieve efficient communication and GPU memory utilization.
Communication optimization
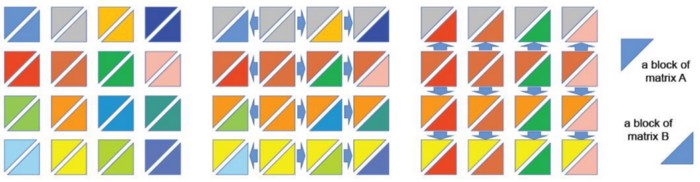
Suppose there are q×q processors, and model parameters are equally split into q×q sub-matrices distributed to the corresponding processors. Taking the calculation of C=AB as an example, SUMMA treats matrix multiplication as the sum of a set of outer products. The A and B matrices are divided into a series of submatrices by columns and rows, respectively.
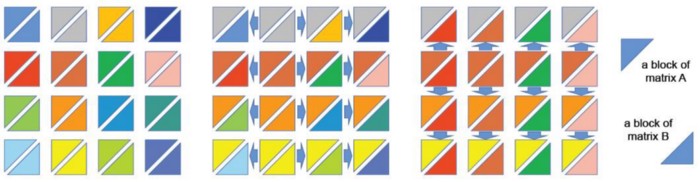
As shown above, there are 16 processors, taking the submatrix in the second row and second column as an example. To calculate the outer products, all processors in the second column broadcast their A submatrices to each processor in the same row; all processors in the second row broadcast their B submatrices to each processor in the same column. Then, each processor locally calculates the multiplication of the sub-matrices of A and B.
Due to the use of a two-dimensional grid structure, communication costs can be reduced significantly when computing very large AI models compared to a one-dimensional structure. For example, for 100 GPUs (10×10), supposed we adopt NVIDIA Megatron’s 1D tensor parallelism, each GPU would need to communicate with other 99 GPUs, resulting in 100×99=9900 communications for a single computation. Using 2D tensor parallelism of Collosal-AI, each GPU only needs to communicate with 9 GPUs. 100 × 9 = 900 communications are required for a single computation, which can significantly improve communication efficiency.
Regarding the implementation, the structural mapping of the multilayer perceptron and self-attentive components in the model is shown in the following figure.

GPU Memory Management
Since the Transformer is composed of N identical Transformer layers stacked together in sequence, this provides the possibility of reusing GPU memory space, i.e., the same computation in each layer can use the same piece of GPU memory space. Therefore, in addition to activation checkpointing, we allocate various different buffers for workspace, forward propagation, backward propagation, parameter gradient and conjunction to store the local submatrices, activation and gradient, etc., and reuse the GPU memory space for different layer computations, which greatly improves the utilization of GPU memory.
Experiments
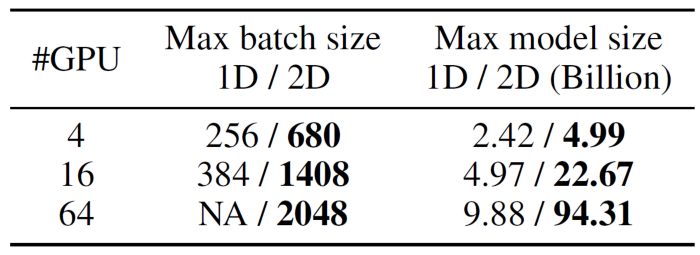
On a cluster with 64 NVIDIA A100 40GB GPUs, taking ViT-Large/16 pre-training as an example, we carried out experiments on ImageNet-1K dataset.
Compared to NVIDIA’s 1D tensor parallelism, 2D tensor parallelism achieves 5.3× maximum batch size, or 9.55× the maximum model size. Note that since there are only 16 attention heads in ViT-Large/16, using 1-dimensional tensor parallelism scales the standard ViT-Large/16 to a maximum of 16 GPUs.
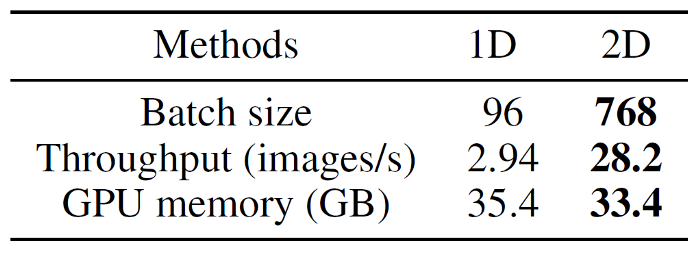
To compare the speed at large-scale parallelism for large AI models, we set the number of attention heads of ViT-Large/16 to 64 and the number of hidden size to corresponding 4096, which means the number of model parameters is about 5 billion. Due to the advantages of 2D tensor parallelism in terms of GPU memory utilization, allowing the use of larger batch sizes, and optimization for communication, a 9.6× training speedup is achieved.
Due to the limitation of hardware resources, the current experiments only show the scalability of 64 GPUs. In experiments with larger-scale parallelism and larger models, 2D tensor parallelism will achieve more obvious advantages.
Highest parallel dimension
Multi-dimensional tensor parallelism not only has excellent performance, but also is compatible with existing parallel modes such as data parallelism, pipeline parallelism, and sequence parallelism, which together form the world’s highest parallel dimension AI training system, Colossal-AI, providing a better option for low-cost and fast training of super large AI models.
More Features
Colossal-AI is still in the beta testing stage, and more amazing results will be released in the near future.
We will also make intensive iterative updates based on user feedback and established plans to provide users with the official version as soon as possible.
The Colossal-AI team will also release several open-source subsystems within one year, eventually forming a rich solution for high-performance AI platforms to fully meet the different needs of users.
Join Us
The core members of HPC-AI Tech team are from the University of California, Berkeley, Stanford University, Tsinghua University, Peking University, National University of Singapore, Singapore Nanyang Technological University, and other well-known universities in the world. At present, HPC-AI Tech is recruiting full-time/intern AI system/architecture/compiler /network/CUDA/SaaS/k8s and other core system developers.
HPC-AI Tech provides competitive salaries. Excellent applicants can also apply for remote work. You are also welcome to recommend outstanding talents to HPC-AI Tech. If they successfully sign up for HPC-AI Tech, we will provide you with a recommendation fee of hundreds to thousands of dollars.
Resume delivery mailbox: hr@hpcaitech.com
Portal
Paper Address: https://arxiv.org/abs/2110.14883
Project Address: https://github.com/hpcaitech/ColossalAI
Document Address: https://www.colossalai.org/
Reference:
[1] ZeRO: Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. (2019) ZeRO: memory optimizations toward training trillion parameter models. arXiv:1910.02054 and In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '20).
[2] ZeRO-Offload: Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, Yuxiong He. (2021) ZeRO-Offload: Democratizing Billion-Scale Model Training. arXiv:2101.06840 and USENIX ATC 2021.
[3] ZeRO-Infinity: Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, Yuxiong He. (2021) ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning. arXiv:2104.07857 and SC 2021.
Comments