Today’s AI models are great at specializing at one task. Whether that be object detection over a particular domain of labels (for example cats and dogs), or generating natural language (e.g. a book or an essay) based on a prompt. To ask a model to do both, however, and you get into very murky territory. That is until 2021 where Google’s Jeff Dean came up with what may be the future of deep learning: Pathways. Pathways is a multi-modal, sparse, deep learning architecture that can generalize to millions of tasks. It is an incremental step towards a more artificially general and intelligent machine.
Nevertheless, compared to the original Transformers architecture, Pathways Language Model(PaLM) has made a series of bold innovations. However, due to its inordinate complexity, it, once again, places the burden on programmers to implement it efficiently on modern hardware. Moreover, significant parts of PaLM are not open sourced, making it difficult to implement parts of it on available hardware, such as GPUs.
Fret not! The Colossal-AI team has implemented the model structure of PaLM and applied several state-of-the-art (sota) high performance computing (HPC) techniques to its implementation, in a parallelised manner, across GPUs, extracting the very last iota of performance.
Let’s talk about the Colossal-AI project, Pathways and our efficient implementation.
If you feel interested, do check out our GitHub repo: https://github.com/hpcaitech/PaLM-colossalai
About Colossal-AI
Colossal-AI is a deep learning system that makes it easy to write performant parallel code for your large AI models. It is based on PyTorch and provides an entire ecosystem to scale up your training to the next level.
GitHub page: https://github.com/hpcaitech/ColossalAI
Colossal-AI’s claim to fame is that it supports a variety of distribution methods, including tensor parallelism, pipeline parallelism, zero-redundant data parallelism etc… We have provided, as examples, efficient implementations of BERT, GPT and ViT that support hybrid levels of parallelism (combining multiple distributed acceleration methods at once). Evolving with the machine learning community, we now attempt to support the PaLM model’s distributed training.
About Pathways
Pathways is the next stage in the evolution of deep learning architectures. It is a large multi-modal system that is capable of generalizing across as many as millions of tasks. Unfortunately, Pathways is built for Google’s needs. As such, it is built over extremely special hardware (TPUs) and over its own special network as well. These mean that, whilst efficient in the Google ecosystem, additional works need to be carried out to scale to accessible hardwares (GPUs) for the society. The model size of PaLM is quite huge with 540 billion parameters, which strongly affects the efficiency a naive data parallel method can grant. The question that begs to be answered is: can we use our common GPU clusters to implement a performant PaLM Model? Well, the engineers of HPC-AI Tech have proposed an answer with Colossal-AI.
But before we delve into the implementation details, let’s talk about the intricacies of what makes the PaLM model great.
PaLM Model Explained
Compared to the regular Transformer architecture, PaLM innovates primarily in following ways:
- It uses the SwiGLU activation function over the ReLU, GeLU or even Swish activation functions (these latter activations are commonly used in Transformer architectures).
2. Parallelised Transformer layer that differs from normal parallelisation
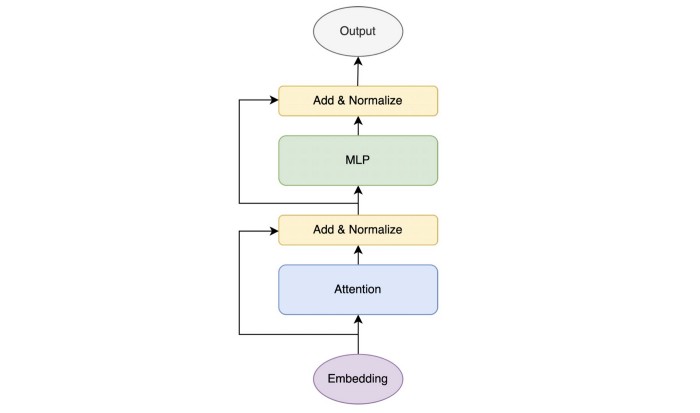
The transformer model has two main modules: Attention module and MLP module. In general, the attention layer usually precedes the MLP module. However, in PaLM, the attention and MLP layers are combined together for an overall more compute-efficient architecture.
As shown in Fig. 1, the normal Transformer layer can be represented as follows
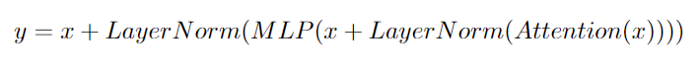
While detailed as Fig. 2, the Transformer layer of PaLM can then represented as
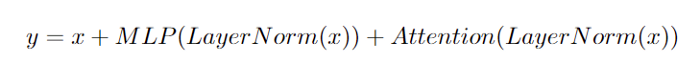
According to the paper, fusing the first linear layer of the MLP and the first linear Attention layer can bring an improvement of about 15%! However, we found that even the second layers can be fused, granting an even greater improvement. The architecture of the model after fusion can thus be represented in the following diagram.

3. Multi-Query attention mechanism
Unlike conventional multi-head attention, PaLM has only one head for both the keys and values, while the queries maintain multiple heads as normal multi-head attention. This reduces the number of parameters and thus increases both the speed of training and inference, whilst retaining great model performance on accuracy. We provide both multi-query and multi-head mechanisms in our implementation.
4. Both linear and layernorm layers do not use bias weights, which researchers from Google claim is beneficial for training stability.
We firstly reproduced the PaLM model architecture on one GPU according to the PaLM paper’s description. Here we have referred following repo for the reproduction: https://github.com/lucidrains/PaLM-pytorch
ColossalAI’s Enhanced Parallelisation
Colossal-AI comes to help users easily implement the PaLM model in a parallel manner. Let us describe some of the interesting features that Colossal-AI permits us to write a parallelised, distributed PaLM.
Tensor parallel
One of the core tenets of Colossal-AI is ease of use. That’s why we built a system that is consistent with PyTorch’s interface and does not require deep learning practitioners to learn a completely new framework (yet again). For example, simply replacing toch.nn.Linear with colossalai.nn.Linear will enable users to enjoy all of Colossal-AI’s sota HPC techniques (such as tensor parallelism).
More information can be found here: https://www.colossalai.org/docs/features/1D_tensor_parallel/
Tensor parallelism afforded in an intuitive easy to use manner by Colossal-AI is important, particularly in the quest to implement an efficient Pathways model.
Due to PaLM’s special setting in its attention structure, Colossal-AI needs to deal with a problem involving query, key, and value(Q, K, V). Existing Tensor parallelism in Colossal-AI cuts the last dimension of query, key and value (the first dimension may be cut depending on the parallel mode, but it does not affect the computation, so it will be ignored below), and since key and value are single-head, we need to perform additional communication to ensure their correctness. Here we use B to denote batch size, S to denote sequence length, H to denote hidden size, N to denote the number of attention heads, A to denote the size of a single attention head, and P to denote the number cuts of tensor parallel, where H = NA.
In the non-parallel case, the size of our multi-head Q is (B, S, H) and the size of single-head K and V is (B, S, A). By converting Q into (B, S, N, A), we can directly compute attention together with K and V. But in the parallel situation, Q is (B, S, H/P) and K and V are (B, S, A/P). We can change Q into (B, S, N/P, A) so that we can cut the head dimension of the Q on different GPUs. But this is still not computable because the values on K and V are not sufficient to form a complete attention head, so we need to introduce an additional all-gather operation to form a completed head, i.e., (B, S, A/P) -> (B, S, A). In this way, normal attention computation can be performed.
ZeRO Parallelism
Colossal-AI can additionally provide a memory optimisation by removing redundant operations in the data-parallel approach, dubbed ZeRO parallelism (initially proposed by Microsoft). We can combine the ZeRO parallel approach with different forms of tensor parallelisms as mentioned above to enjoy further gains in efficiency.
Heterogeneous Training
To support large-scale AI model training on a single node, we implement a dynamic heterogeneous memory management mechanism. We optimize the placement of tensors on CPUs and GPUs so as to minimize movement of large tensors. In this manner, we thus leverage heterogeneous memory efficiently.
Training process
The training process is as simple as it gets with Colossal-AI. One simple configuration file can specify what parallel approaches we require. In the PaLM training process, we specify tensor parallelism as well as the configuration of ZeRO.

With this configuration file setup, we are good to go! We can use a simple API: colossal.initialise, to build our training engine and provide us with APIs that resemble PyTorch style code. We can use Colossal-AI very easily in this manner for large-scale training without sacrificing performance.

Performance Testing
We tested all our results on a single server with 8 A100 40GB GPUs. Our network consists of NVLink to interconnect adjacent pairs of GPUs at high speed, and PCI-E between four pairs of GPUs.
We constructed a PaLM structured network with 8 billion parameters and trained it using a hybrid parallel strategy (a mix of 1D, 2D, 2.5D Tensor Parallel approaches as well as the ZeRO optimization). Colossal-AI can additionally switch between training strategies inexpensively by simply changing the comprehensible configuration file.
In the following figure, b denotes the batch size of each data parallel process group, XXtpY denotes the tensor-parallel strategy, XX denotes the 1D, 2D, 2.5D parallel scheme, and Y denotes the parallel degree of tensor parallelism. zeroX denotes in ZeRO parallelism setting with a ZeRO parallelism of degree X. Here we have data parallel degree times model parallel degree quals to the total number of GPUs.

Through numerous experiments, we found that heterogeneous training is a necessity. All the aforementioned schemes enjoyed greater compute efficiencies when implemented with heterogeneous training. Without it, running a model with 8 billion parameters would not be possible.
Specifically, in the cases of 2,4 and 8 GPUs, we find that a 1D tensor parallel degree of 2 works best. This manifests in our setup because the communication bandwidth between adjacent GPUs is high. With the aforementioned optimal configuration, most of the communication is placed between adjacent GPUs. With different network configurations, 2D or even 2.5D tensor parallelism could be more apt. However, with colossal-AI, all that needs to be changed is a simple configuration file, and training can be adapted to a new parallel configuration.
Summary
To conclude, we would like to repeat that we have reproduced the architecture of PaLM. Unfortunately, due to the scarcity of computational resources, we could not fully reproduce the full 100 billion parameter model. Moreover, due to PaLM not being open-sourced, our implementation could deviate slightly from the original implementation of Google’s.
If you have any questions, please feel free to raise an issue or a PR on Github and we will try our best to answer them as soon as possible!
Funding
HPC-AI Tech raised 4.7 million USD from top VC firms in just 3 months after the company was founded. For more information, please email contact@hpcaitech.com.
Comments