How long does it take to pre-train Vision Transformer (ViT), the hottest AI model in computer vision, from scratch? The latest answer given by Colossal-AI system is half an hour — a new world record!
Open source address: https://github.com/hpcaitech/ColossalAI
Acceleration Difficulties
Bigger models
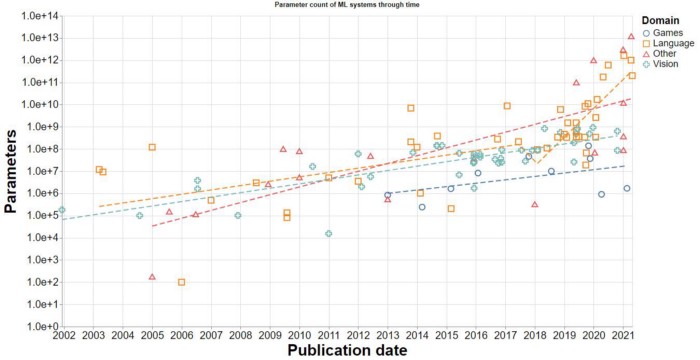
In recent years, with the continuous improvement of AI performance, the number of AI model parameters has also shown explosive growth, from AlexNet, ResNet to BERT, GPT, MoE …, the parameter magnitude of AI models has been constantly refreshed and now exceeds trillions, which makes the training cost rise sharply. Just to train the 100 billion parameters GPT-3 released by OpenAI in 2020, even with a piece of the most advanced NVIDIA A100 GPU for training, it still needs to wait for more than 100 years. Obviously, how to accelerate the AI training process has become one of the biggest pain points in the AI industry.
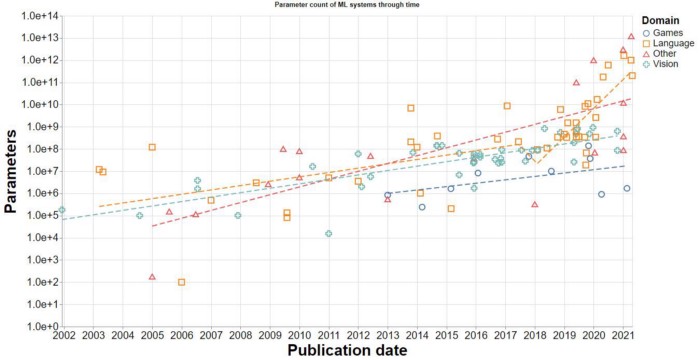
Convergence difficulty
A common way to speed up AI model training is to implement large-batch training with the help of data parallelism, i.e., by increasing the batch size, thus reducing the number of iterations and eventually achieving a significant reduction in training time. But large-batch training usually leads to convergence difficulty and performance degradation on the test set due to the generalization gap.
Limited supercomputing efficiency
As a result, more and more tech giants are choosing to use high-performance computing technologies to accelerate computational tasks in parallel using hundreds or even thousands of the best processors with the help of supercomputer clusters, such as Google’s TPU Pod and Nvidia’s SuperPOD.

However, even supercomputers worth hundreds of millions of dollars face the bottleneck that computational efficiency cannot be further improved when the hardware stack reaches a certain number, wasting a large number of computational resources. In addition, distributed parallel programming usually requires expertise related to computer system and architecture, which further increases the training cost of cutting-edge AI models.
Acceleration in Colossal-AI
Large Batch Data Parallelism
On ImageNet-1K dataset (1.28 million images), the pre-training of ViT requires using the whole dataset 300 times, and it would take about three days to pre-train ViT-Base/32 using one NVIDIA A100 GPU with batch size 128.
Using LAMB, the large batch optimizer provided by Colossal-AI, we can successfully overcome the difficulties of large batch optimization and quickly extend the training process to 200 A100 GPUs through data parallelism with 32K batch size, and complete the ViT-Base/32 pre-training in only 0.61 hours and maintain accuracy. For the more complex pre-training ViT-Base/16 and ViT-Large/32, Colossal-AI also completes in only 1.87 hours and 1.30 hours, respectively.
Reproduction Address:
https://github.com/hpcaitech/ColossalAI/tree/main/examples/vit-b16

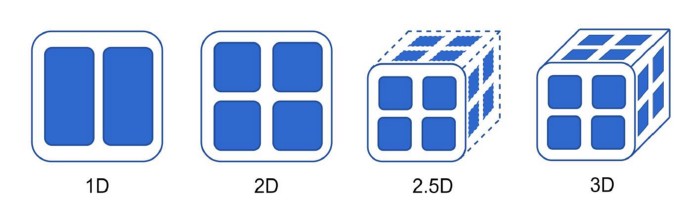
Six-dimensional parallelism
The current mainstream tensor parallelism schemes, such as Microsoft’s DeepSpeed and NVIDIA’s Megatron, are one-dimensional tensor parallelism, which means that each processor needs to communicate with all other processors. However, communication between processors, especially multi-machine cross-node communication, not only can seriously slow down the running speed, occupy a lot of extra memory of processors, but also the energy consumption cost is very high. To address this pain point, Colossal-AI proposes to use multidimensional tensor parallelism: tensor parallelism in 2/2.5/3 dimensions. Colossal-AI is also fully compatible with existing parallel modes such as data parallelism, pipeline parallelism and sequence parallelism, which together form Colossal-AI’ “six-dimensional parallelism”, far exceeding the three-dimensional parallelism of Microsoft and NVIDIA, and the related technology can be extended to the field of inference acceleration easily.
World’s No.1 in Hotlist
As the core of deep learning framework, Colossal-AI decouples “system optimization” from “upper framework” and “lower hardware”, and provides a convenient implementation of cutting-edge technologies such as multi-dimensional parallelism, large batch optimizers, and zero offload of redundant memory in a plug-and-play manner. It is easy to expand and use, and only a small amount of code modification is required to prevent users from learning complex distributed system knowledge. For processors such as GPUs, the average computing power cost of using dense clusters will be much lower than that of scattered use, so it can not only save training time, but also greatly reduce the cost of computing power.
Colossal-AI has been widely followed once open-sourced, ranking first in the world in the Python direction of GitHub Trending (fifth in the world in all directions).
More Features
Colossal-AI is still in the beta testing stage, and more amazing results will be released in the near future.
We will also make intensive iterative updates based on user feedback and established plans to provide users with the official version as soon as possible.
The Colossal-AI team will also release several open-source subsystems within one year, eventually forming a rich solution for high-performance AI platforms to fully meet the different needs of users.
Join Us
The core members of HPC-AI Tech team are from the University of California, Berkeley, Stanford University, Tsinghua University, Peking University, National University of Singapore, Singapore Nanyang Technological University, and other well-known universities in the world. At present, HPC-AI Tech is recruiting full-time/intern software engineers, AI engineers, SaaS engineers, architecture/compiler/network/CUDA, and other core system developers. HPC-AI Tech provides competitive salaries.
Excellent applicants can also apply for remote work. You are also welcome to recommend outstanding talents to HPC-AI Tech. If they successfully sign up for HPC-AI Tech, we will provide you with a recommendation fee of hundreds to thousands of dollars.
Resume delivery mailbox: hr@hpcaitech.com
Portal
Paper Address: https://arxiv.org/abs/2110.14883
Project Address: https://github.com/hpcaitech/ColossalAI
Document Address: https://www.colossalai.org/
Reference:
https://github.com/NVIDIA/Megatron-LM
https://towardsdatascience.com/parameter-counts-in-machine-learning-a312dc4753d0
Comments