FP8, with its unique numerical representation, can improve training speed, reduce memory usage, and ultimately lower training costs in large model training while maintaining a certain level of precision.
The mixed precision training of the AI large model development system Colossal-AI has been upgraded again, now supporting the new generation of mixed precision training scheme with BF16 (O2) + FP8 (O1). With just a single line of code, mainstream LLM models can achieve an average 30% acceleration, reducing the corresponding large model development costs while ensuring training convergence. There is no need to introduce additional hand-written CUDA operators, avoiding lengthy AOT compilation times and complex compilation environment configurations.
Open source address: https://github.com/hpcaitech/ColossalAI
FP8 mixed precision training
Low precision computation has consistently been a trend in GPU hardware development, evolving from the early FP32 to the widely used FP16/BF16, and now to FP8, supported by the Hopper series chips (H100, H200, H800, etc.). Low precision computation offers faster processing speeds and lower memory requirements, perfectly aligning with the hardware demands of the large model era.
Currently, the biggest factor influencing FP8 mixed precision training results is the scaling recipe. There are two common approaches:
-
Delayed scaling
-
Current scaling
Delayed scaling uses the scaling values from a previous time window to estimate the current scaling and integrates the update of scaling with matrix multiplication (gemm). This method is more efficient but has a greater impact on convergence due to the approximated scaling.
Real-time scaling, on the other hand, calculates scaling based on the current tensor values, which results in lower computational efficiency but has less impact on convergence.According to NVIDIA's report, the difference in computational efficiency between these two scaling strategies is less than 10%.
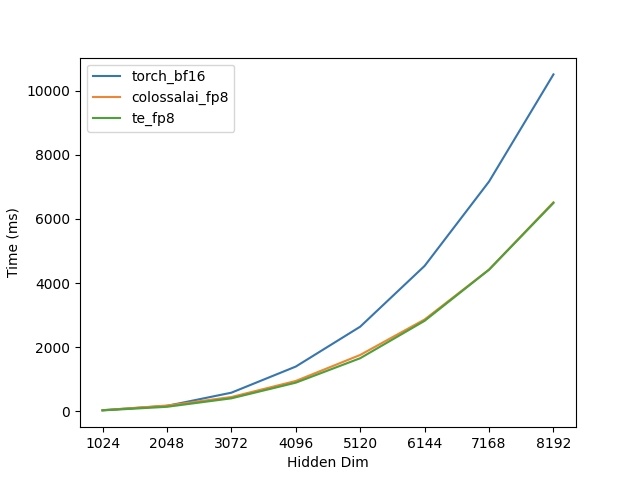
Colossal-AI adopts the real-time scaling strategy, which has minimal impact on training convergence, while achieving performance comparable to other delayed scaling implementations. In tests conducted on a single H100 card for matrix multiplication, it was observed that the larger the matrix size, the more significant the speed-up effect of FP8. Additionally, Colossal-AI's implementation performs almost identically to the Transformer Engine, as shown in Figure 1. However, Transformer Engine requires a complex AOT compilation environment setup and longer compilation times.

Single-GPU GEMM Performance Test
To ensure the experimental results are closer to real-world scenarios, Colossal-AI conducted actual training tests directly on mainstream LLMs.
First, tests were performed on a single H100 GPU. In these tests, Transformer Engine (TE) used its default delayed scaling strategy.


At the same time, convergence tests were conducted, and it can be observed that the loss curve of FP8 mixed precision training closely matches that of BF16, as shown in the figure below.
.png?width=1280&height=847&name=image%20(6).png)
The loss curve for mixed precision training of the LLaMA2-7B model on a single H100 GPU
Colossal-AI also tested performance in a multi-GPU parallel training scenario on H800. When training LLaMA2-7B on a single machine with 8 H800 GPUs, Colossal-AI FP8 achieved a 35% throughput improvement compared to Colossal-AI BF16, and a 94% throughput improvement compared to Torch FSDP BF16.

When training LLaMA2-13B on a single machine with 8 H800 GPUs, Colossal-AI FP8 demonstrated a 39% throughput improvement compared to Colossal-AI BF16.

When training the Cohere Command-R 35B model on a 2-machine, 16-GPU H800 setup, Colossal-AI FP8 showed a 10% throughput improvement compared to Colossal-AI BF16.

Based on NVIDIA’s report and our testing experience, we have developed some preliminary insights on optimizing FP8 mixed precision training performance:
-
Minimize the use of tensor parallelism and replace it with pipeline parallelism when possible.
-
The larger the model's hidden size, the more significant the acceleration effect.
-
Models with a high proportion of matrix multiplication benefit more from acceleration.
In the aforementioned experiments, the acceleration effect was less pronounced for the Command-R 35B model because it utilized tensor parallelism.
Colossal-AI offers broad support for FP8, making it compatible with various parallelism methods in mixed precision training. To use it, you only need to enable FP8 when initializing the plugin.
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin...plugin = LowLevelZeroPlugin(..., use_fp8=True)plugin = GeminiPlugin(..., use_fp8=True)plugin = HybridParallelPlugin(..., use_fp8=True)Beyond this, no additional code or AOT compilation is required.
Open source address: https://github.com/hpcaitech/ColossalAI
Comments