
There’s no two ways about it, we’re in the middle of an AI emergence. In this wave, both enterprises and countries increasingly demand computing power for AI applications. A new trend is consequently emerging: building AI infrastructure at a macro level — distributing resources globally, across countries or even continents! This, however, creates a host of new issues, one of which is the rather important aspect of managing the delay in between computers that are physically far apart.
Crucially, this is coming at a time where data privacy issues proliferate the computing industry. Now, intuitively, separating computers over vast distances seems to make it even easier for data leaks to manifest!
Fret not, to counter some of these issues we propose: Sky Computing. A framework that successfully utilizes techniques from geo-distributed computing that accelerates federated learning by 55%, thereby simultaneously upholding user data privacy.
Whoa, I know there’s a lot of fancy terms here, so let’s dissect these one by one.
Check out the project over here:
https://github.com/hpcaitech/SkyComputing
Geo-distributed Computing
As deep learning continues to evolve, the size of models continues to grow at a very high rate. This means that current mainstream models, such as BERT and GPT-3, have hundreds of millions of parameters. While these models have made great strides in performance improvement, they have also put great pressure on storage and computing. To combat the pressure levied on these devices, distributed machine learning has emerged, often using a large number of high-speed interconnected processors of the same type — also known as supercomputers.

Geo-distributed computing takes this paradigm a step further. It combines computing resources with different computing and communication capabilities together as a large cluster. The caveat is that the computing resources that make up the system can be spread across vast distances. Collectively, the resources within the cluster work in conjunction to accomplish large computing tasks. Over here, the individual constituents of the geo-distributed system can be computing servers or small intelligent devices.
Currently, geo-distributed computing is gaining more and more attention as a new form of heterogeneous computing. In China, for example, with the implementation of the “East digital West Computing”, more computing resources will be distributed to various regions in the west. Coordinating the joint work of such computing clusters, oftentimes far apart with heterogeneous computing capacities, is an increasingly relevant research program that will induce enormous benefits on high performance computing applications.
Moreover, in recent years, more and more enterprises are choosing to deploy their data on the cloud — an example of an, oftentimes, large scale geo-distributed system. Relying on such systems, however, is risky due to their inability to guarantee privacy and reliability of stored data.
So what’s happening is that, due to business needs, companies are increasingly migrating to large scale geo-distributed systems. This means that the two issues highlighted above: precariously managing exorbitant communication costs in between devices, and the inability to guarantee privacy and the reliability of stored data, are problems that are of special interest.

Federal learning
To address these issues, Google proposed the concept of federated learning in 2016: a cryptographically enhanced distributed machine learning technique. As the name suggests, it unites small and large data silos by building a virtual “federation”. Each data island is like a state in this “federation”, maintaining a certain degree of independence (e.g., trade secrets, user privacy), but also being able to work together without sharing data with the outside world to improve the effectiveness of AI models. Currently, federated learning is widely used in the model training of smart terminals, such as Siri and Alex.
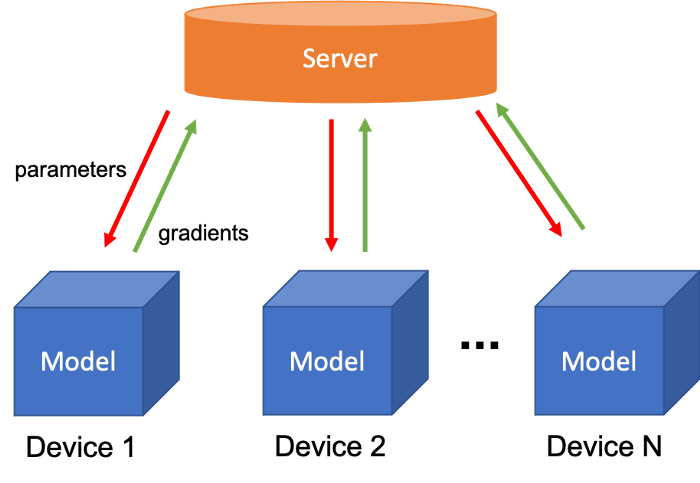
In existing federated learning model parallelism, models are uniformly distributed across individual training devices. However, in such a scenario training devices are typically users’ smart terminals, which differ widely in their performance. Uniformly distributing models in such a scenario thus usually results in communication bottlenecks.
This arises due to the infamous Cannikin Law: the water capacity of a barrel is determined by the shortest board. Applying Cannikin Law to federated learning, we can see that a similar phenomenon manifests: the training speed is determined by the slowest device.
For example, a smartphone and a Raspberry Pi in the same model parallel federated learning task would be assigned the same number of tasks despite the fact that the computing power of the smartphone far exceeds that of the Raspberry Pi. Consequently, the smartphone is oftentimes forced to sit idle and wait for the Raspberry PI’s task to complete.

Sky Computing
Sky computing is a technique that addresses all of these issues by intelligently connecting cloud servers of different sizes and capabilities. It takes a load balancing approach to achieve higher levels of utilization of devices belonging to a heterogeneous cluster whilst only accessing user data through federated learning to avoid any data leakage.
Let’s talk a little bit about the different aspects of Sky Computing.
Load Balancing
To solve the problem of load balancing, we must first understand what “load” is. In a computer, no matter what kind of operation is performed, the load can be understood as the “time required to complete a task”. Since the total amount of computation for training a model in the federated learning context is fixed, if we can intelligently allocate computation tasks in an adaptive way, we can make each device take the same amount of time to complete the computation task and ensure a more optimal time for overall training. In order to get such a good allocation, we need to gather information about the model and device first, and then perform the appropriate allocation operation. We, therefore, need to train the model in two phases: benchmarking followed by allocation.
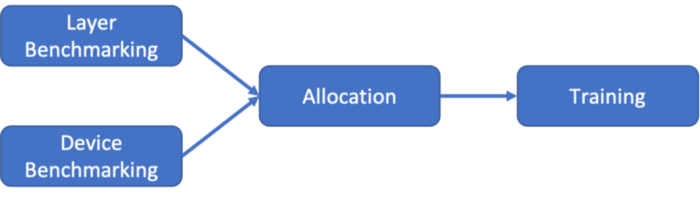
Benchmarking
In the benchmarking phase, Sky Computing needs to collect data from two dimensions: the model and the device. In the model dimension, it collects the required memory footprint and computation for each layer of the model. By combining the expected memory footprint of the model with the available memory of the device, memory overflow can be avoided. Moreover, the greater the amount of computation required for a task, the longer it takes for the same device to complete. In the device dimension, it collects data pertaining to communication latency, computational power and memory availability. These factors are influenced by the network environment, current operating load and other factors. For devices with strong computing power and low communication latencies but with little available memory, as many model layers (computational tasks) as possible should be allocated without overflowing memory. Since Sky Computing is a load-balanced federated learning system, we are only interested in the capabilities of the devices with respect to how they run machine learning programs during the benchmarking phase. This computational ability of a machine to perform AI tasks is measured by running small machine learning test tasks on each device.
Allocation
After benchmarking, Sky Computing leverages this information in the allocation phase, where it allocates tasks to devices. In general, allocating tasks to devices based on devices’ performance is a NP hard problem. Sky Computing can, nonetheless, leverage heuristics to approximate a good-enough solution to allocate such tasks.
Sky Computing’s allocation algorithm proceeds in two-stages: pre-allocation followed by distribution adjustment. In the pre-allocation stage, Sky Computing allocates the model according to the actual available memory size of the device and uses this to compute the initial workload on each device. In the distribution adjustment stage, Sky Computing makes dynamic adjustments according to the loads of each device and iteratively reduces the load of the whole system.
Performance
We verified the performance of Sky Computing in a computing cluster and controlled several key factors to verify their impact on Sky Computing. Throughout all our experiments, we used the forward and backward propagation times as metrics. In addition, we consistently compare it to the optimal allocation in all of our experiments.
Experiments
We tested three allocation methods (even: uniform allocation, heuristic: heuristic algorithm, and optimal: optimal allocation). We recorded the performance of each allocation method across a variety of model sizes and devices of differing computational capacities. It can be seen that the effect of our heuristic algorithm is remarkable as both the number of devices and the depth of the model increase. In an experimental environment with 160 hidden layers of 64 nodes, Sky Computing can accelerate computation by 55% over a uniformly distributed allocation.

In our experiments, computing the optimal allocation was already difficult at a mere 64 nodes. It is thus not a practical method to use in a real life, production setting, but merely as a reference to compare Sky Computing’s efficacy.
More Features
Sky Computing is our successful attempt to accelerate federated learning by exploiting the features of geo-distributed computing. It achieves a performance improvement of up to 55% over current allocation methods. The project is still in the developmental stage, and we will conduct more experiments in the future as well as iterate on its design to provide more features to Sky Computing’s end users.
We welcome you to actively raise issues and PRs, and work together to build this AI infrastructure and liberate AI productivity~
Portal
Paper Link: https://arxiv.org/abs/2202.11836
Project Link: https://github.com/hpcaitech/SkyComputing
Join Us
HPC-AI Tech is a global team and the core members are from the University of California, Berkeley, Stanford University, Tsinghua University, Peking University, National University of Singapore, Singapore Nanyang Technological University, and other top universities in the world. Currently, HPC-AI Tech is recruiting full-time/intern AI system/architecture/compiler/network/CUDA/SaaS/k8s core system developers, open source program operators, and sales personnel.
HPC-AI Tech provides highly competitive compensation packages. Our staff can also work remotely. You are also welcome to recommend outstanding talents to HPC-AI Tech. If they successfully join HPC-AI Tech, we will provide you with a recommendation fee of thousands of US dollars.
Resume delivery mailbox: contact@hpcaitech.com
Funding
HPC-AI Tech raised 4.7 million USD from top VC firms in just 3 months after the company was founded. For more information, please email contact@hpcaitech.com
Reference
https://arxiv.org/abs/2202.11836
https://36kr.com/p/1619922542065412?channel=wechat
https://pdfs.semanticscholar.org/b8dc/bc29485d3ea6c0fe6ddab370ca055b9fb746.pdf
Comments