When it comes to training large AI models, people will think about using thousands of GPUs, expensive training costs, and only a few tech giants can afford them. While AI users, like researchers from startups or universities, could do nothing but get overwhelmed by news about large models~
Now, a PC with only one GPU can train GPT with up to 18 billion parameters, and a laptop can also train a model with more than one billion parameters. Compared with the existing mainstream solutions, the parameter capacity can be increased by more than ten times!
Such a significant improvement comes from Colossal-AI, which is an efficient training system for general large AI models. Best of all, it’s completely open-sourced and requires only minimal modifications to allow existing deep learning projects to be trained with much larger models on a single consumer-grade graphics card, allowing everyone to train large AI models at home! In particular, it makes downstream tasks and application deployments such as large AI model fine-tuning and inference much easier!
By providing various popular efficient parallelisms, Colossal-AI could also help its users easily deploy existing projects to large-scale computing clusters.
Check out the project over here: https://github.com/hpcaitech/ColossalAI
Tech giants strive for large AI models
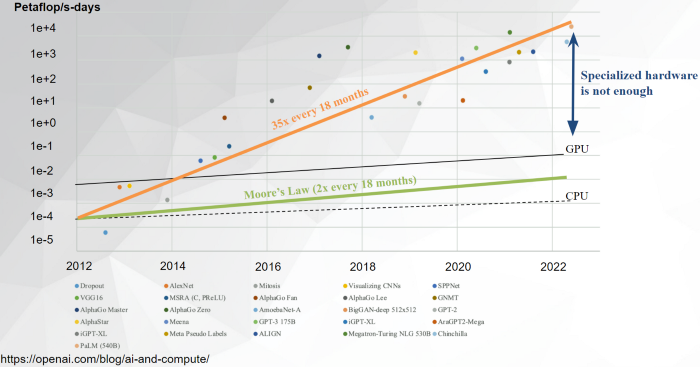
After Google proposed the BERT model with 300 million parameters in 2018, the large models’ parameter records have been updated many times in just a few years, such as GPT-3 with 175 billion parameters proposed by OpenAI, MT-NLG with 530 billion parameters introduced by Microsoft and NVIDIA jointly…
The dense model has achieved the scale with more than hundreds of billions of parameters, while the sparse Mixture of Experts (MoE) model, such as the Switch Transformer released by Google in 2021, has brought the number of parameters to the level of trillion.
However, training such large models from scratch might be extremely expensive. It usually requires hundreds or even thousands of professional high-performance GPUs such as NVIDIA A100 at the same time. If we use a dedicated InfiniBand high-speed network to build a supercomputer cluster, the cost for training could even reach ten million dollars.
Use a single consumer-level GPU to train large AI models
It’s obvious that AI users like university students and individual developers could not afford such high costs to train large models, and the most popular computing resources are the NVIDIA RTX GPUs for this kind of people in the AI community.
In order to enhance AI productivity, allow large models to benefit more developers, and truly realize our vision to make the use of large AI models “fast and cheap”, Colossal-AI requires only a few lines of codes to achieve a ten-fold increase in the capacity of model training.

On all types of hardware, Colossal-AI performs better than vanilla PyTorch and mainstream distributed solutions such as Microsoft’s DeepSpeed.
For the representative of large models — GPT, Colossal-AI is capable of training it with up to 1.5 billion parameters on a gaming laptop with RTX 2060 6GB. For a PC with RTX3090 24GB, Colossal-AI could help its users to train GPT with 18 billion parameters. For high performance graphics cards such as Tesla V100, Colossal-AI could bring significant improvements as well.

Colossal-AI has also successfully implemented Google’s PaLM (Pathways Language Model), which was published recently. It has also shown excellent performance improvements on various hardware, while Microsoft DeepSpeed has not published its official PaLM implementation.

Key technology: Enhanced heterogeneous training
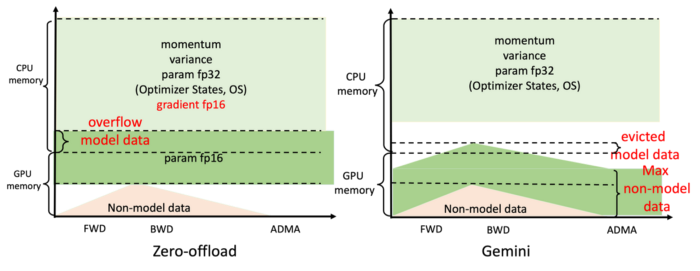
The biggest problem with using a single consumer-grade GPU to train a large AI model is that the GPU memory capacity is extremely limited, which severely restricts the model parameters that can be accommodated. The ZeRO-offload method proposed by Microsoft DeepSpeed tries to split the model and utilize the CPU memory with larger capacity and lower cost. At present, there have been several modified versions based on DeepSpeed for heterogeneous training. But as shown on the left part of the figure below, when the GPU memory is insufficient for its corresponding model requirements, the system will crash even if there is still memory available on the CPU.

Different from the derivatives based on DeepSpeed, Colossal-AI team built its core technologies such as ZeRO from scratch, solving current problems like DeepSpeed only statically divides model data between CPU and GPU memory, and only uses fixed memory layout for different training configurations. A lot of improvements have been made by Colossal-AI to improve the efficiency of the usage of GPU and CPU memory. After all, CPU memory is much cheaper than high performance graphics cards with large memory.
The Gemini mechanism designed by Colossal-AI, efficiently manages and utilizes the heterogeneous memory of GPU and CPU, so that tensors are dynamically distributed in the storage space of CPU-GPU during the training process, therefore model training can break the GPU’s memory barrier.
We take advantage of the iterative nature of the deep learning network training process, and divide the training into two stages: warmup stage and non-warmup stage according to the number of iterations. In the initial warmup phase, memory information is monitored; in the non-warmup phase, the collected information is used to efficiently move tensors to minimize CPU-GPU data movement.
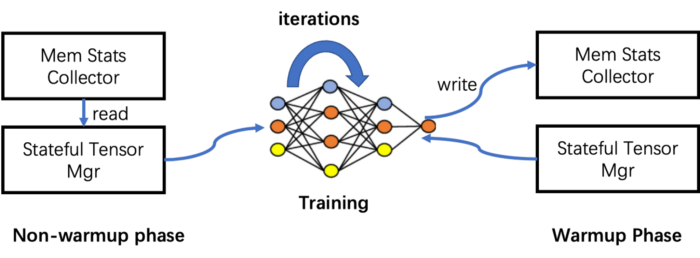
It sounds easy, but its implementation is troublesome. It is actually hard to obtain the memory usage of non-model data, because the life cycle of non-model data is not managed by users, and the existing deep learning frameworks do not expose the tracking interface of non-model data to its users. Secondly, non-framework overhead such as CUDA context also needs to be considered.
Colossal-AI obtains the usage of CPU and GPU memory by sampling in the warmup stage. While the usage of non-model data can be obtained by comparing the maximum system memory usage and model memory usage between two moments. The memory usage of the model could be known by querying the memory manager, as shown by the black solid line in the figure below.
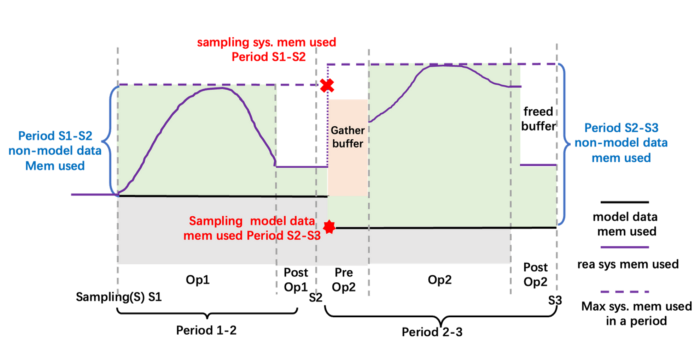
All tensors from models are managed by the memory manager, and each tensor is marked with information of states, including HOLD, COMPUTE, FREE, etc. According to the dynamically queried memory usage, Colossal-AI changes states of tensors, and adjusts positions of tensors continuously. Finally, the efficient usage of GPU and CPU memory is realized, maximizing model capacity and balancing training speed in the case of extremely limited hardware, which is of great significance for AI democratization and low-cost fine-tuning of downstream tasks for large models.
Furthermore: convenient and efficient parallelizations
Parallel and distributed technologies are important methods to further accelerate model training. To train the world’s largest and most advanced AI models within the shortest time, efficient distributed parallelization is still a necessity. Aiming at the pain points of the existing solutions such as limited parallel dimension, low efficiency, poor versatility, difficult deployment, and lack of maintenance, Colossal-AI uses technologies such as efficient multi-dimensional parallelism and heterogeneous parallelism to allow users to deploy large AI models efficiently and quickly with only a few modifications of their codes.
For example, for a super-large AI model such as GPT-3, compared to the NVIDIA solution, Colossal-AI only needs half the computing resources to start training; if the same computing resources are used, the speed could be further increased by 11%, which could reduce the training cost of GPT-3 over a million dollars.

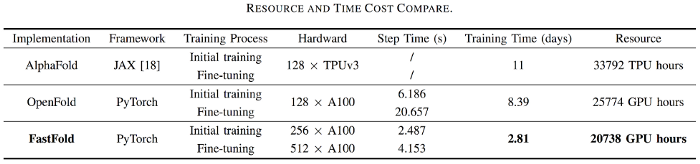
For AlphaFold, which is used for protein structure prediction, our team has introduced FastFold based on the Colossal-AI acceleration scheme. FastFold successfully surpassed other schemes proposed by Google and Columbia University, reducing the training time of AlphaFold from 11 days to 67 hours, and the total cost is lowered as well. Also, in long sequence inference, we achieved a speed improvement of 9.3 ~ 11.6 times.
Besides, Colossal-AI values open source community construction, providing English and Chinese tutorials, and supporting the latest cutting-edge applications such as PaLM and AlphaFold. Colossal-AI will roll out new and innovative features regularly as well. We always welcome suggestions and discussions from the community, and we would be more than willing to help you if you encounter any issues. You can raise an issue here or create a discussion topic in our forum. Your suggestions are highly appreciated here. Recently, Colossal-AI reached No. 1 on the top trending projects on Github, against a backdrop of many projects that have as many as 10K stars.
About us
The core members of the HPC-AI Tech team are from the UC Berkeley, Stanford University, Tsinghua University, Peking University, National University of Singapore, Nanyang Technological University and other well-known universities. Also, they have work experience from tech giants like Google Brain, IBM, Intel, Microsoft, NVIDIA, etc. The company has received seed round funds from many top VC institutions such as Sinovation Ventures and ZhenFund as well.

Prof. Yang You, Founder of HPC-AI Tech
Ph.D., University of California, Berkeley
IPDPS/ICPP Best Paper Author
ACM/IEEE CS George Michael Memorial HPC Fellowship
Forbes 30 Under 30 (Asia 2021)
IEEE-CS Outstanding Newcomer Award in Supercomputing
UC Berkeley EECS Lotfi A. Zadeh Prize

Prof. James Demmel, CSO of HPC-AI Tech
Distinguished Professor, University of California, Berkeley
ACM/IEEE Fellow
Member of the American Academy of Sciences, the Academy of Engineering, and the Academy of Arts and Sciences
Portal
Code
https://github.com/hpcaitech/ColossalAI
Reference
[1] ZeRO: Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. (2019) ZeRO: memory optimizations toward training trillion parameter models. arXiv:1910.02054 and In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '20).
[2] ZeRO-Offload: Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, Yuxiong He. (2021) ZeRO-Offload: Democratizing Billion-Scale Model Training. arXiv:2101.06840 and USENIX ATC 2021.
[3] ZeRO-Infinity: Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, Yuxiong He. (2021) ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning. arXiv:2104.07857 and SC 2021.
Comments